
One of the key mechanisms that allows Wikipedia to maintain its high quality is the use of inline citations. Through citations, readers and editors make sure that information in an article accurately reflects its source. As Wikipedia’s verifiability policy mandates, “material challenged or likely to be challenged, and all quotations, must be attributed to a reliable, published source”, and unsourced material should be removed or challenged with a citation needed flag.
However, deciding which sentences need citations may not be a trivial task. On the one hand, editors are urged to avoid adding citations for information that is obvious or common knowledge—like the fact that the sky is blue. On the other hand, sometimes the sky doesn’t actually appear blue—so perhaps we need a citation for that after all?
Scale up this problem to the size of an entire encyclopedia, and it may become intractable. Wikipedia editors’ time is limited and their expertise is valuable—which kinds of facts, articles, and topics should they focus their citation efforts on? Also, recent estimates show that a substantial proportion of articles have only a few references, and that one out of four articles in English Wikipedia does not have any references at all. This suggests that while around 350,000 articles contain one or more citation needed flags, we are probably missing many more.
We recently designed a framework to help editors identify and prioritize which sentences need citations in Wikipedia. Through a large study that we conducted with editors from English, Italian and French Wikipedia, we first identified a set of common reasons why individual sentences in Wikipedia articles require citations. We then used the results of this study to train a machine learning model classifier that can predict whether or not any given sentence needs a citation —and why—on the English Wikipedia. It will be deployed in the next 3 months to other language editions.
By improving the identification of where Wikipedia gets its information from, we can support the development of systems to help volunteer-driven verification and fact-checking, potentially increasing Wikipedia’s long-term reliability and making it more robust against biases, information quality gaps and coordinated disinformation campaigns
Why do we cite?
To teach machines how to recognize unverified statements, we first needed to systematically classify the reasons why sentences need citations.
We started by examining policies and guidelines related to verifiability in the English, French, and Italian Wikipedias and attempted to characterize the criteria for adding (or not adding) a citation described in those policies. To verify and enrich this set of best practices, we asked 36 Wikipedia editors from all three language communities to participate in a pilot experiment. Using WikiLabels, we collected editors’ feedback on sentences from Wikipedia articles: editors were asked to decide whether a sentence needed a citation and to specify a reason for their choices in a free-text form.
Our methods and our final set of reasons for adding or not adding a citation can be found on our project page.


Teaching a machine to discover citation gaps.
Next, we trained a machine learning model to discover sentences needing citations, and characterize them with a matching reason.
We first trained a model to learn from the wisdom of the whole editor community how to identify sentences that need to be cited. We created a dataset of English Wikipedia’s “featured” articles, the encyclopedia’s designation for articles that are of the highest quality—and also the most well-sourced with citations. Sentences from featured articles that contain an inline citation are considered as positives, and sentences without an inline citation are considered as negatives. With this data, we trained a Recurrent Neural Network that can predict whether the sentence is positive, (should have a citation), or negative (should not have a citation) based on the sequence of words in the sentence. The resulting model can correctly classify sentences in need of citation with an accuracy of up to 90%.
Explaining algorithmic predictions
But why is the model up to 90% accurate? What is the algorithm looking at when deciding whether a sentence needs a citation?
To help interpret these results, we took a sample of sentences needing citations for different reasons, and highlighted words the model considered the most when it classified the sentences. In the case of “opinion” statements, for example, the model assigned the highest weight to the word “claimed”. In the “statistics” citation reason, the most important words to the model are verbs that are often used in reporting numbers. In the case of scientific citation reasons, the model pays more attention to domain-specific words like “quantum”.

Predicting why a sentence needs a citation
Similar to the “reason” field of the [citation needed] tag, we want our model to also provide full explanations of citation reasons. Therefore we created a model that can classify statements needing citations with a reason. We first designed a crowdsourcing experiment using Amazon Mechanical Turk to collect labels about citation reasons. We randomly sampled 4,000 sentences that contain citations from Featured articles, and asked crowdworkers to label them with one of the eight citation reason categories we identified in our previous study. We found that sentences more likely need citations when they are related to scientific or historical facts, or when they reflect direct/indirect quotations.
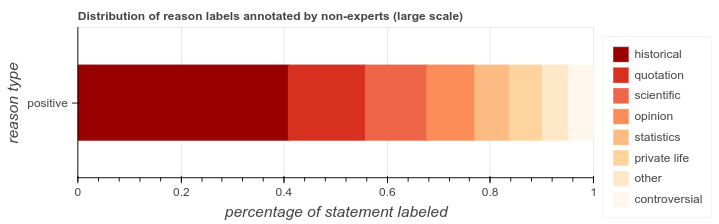
We modified the neural network designed in the previous study, so that it can classify an unsourced sentence into one of the 8 citation reason categories. We retrained this network using the crowdsourced labeled data, and found that it provides reasonable accuracy (precision at 0.62) in predicting citation reasons, especially for classes with a substantial amount of training data.
Next steps: predicting “citation need” across languages and topics
The next phase of this project will involve modifying our models so that they can be trained for any language available in Wikipedia. We will use these multilingual models to quantify the proportion of unverified content across Wikipedia editions, and map citation coverage across different article topics, in order to help editors identify areas where adding high quality citations is particularly important.
We plan to make the source code of these new models available soon. In the meantime, you can check out the research paper, recently accepted at The Web Conference 2019, its supplementary material with detailed analysis of the citation policies, and all the data we used to train the models.
We would love to hear your feedback and comments, so please reach out to us on our project page to help us improve it.
Miriam Redi, Research Scientist, Wikimedia Foundation
Jonathan Morgan, Senior Design Researcher, Wikimedia Foundation
Dario Taraborelli, former Director of Research, Wikimedia Foundation
Besnik Fetahu, Post-doctoral Scientist, L3S Lab Hannover
The authors would like to thank the community members of the English, French, and Italian Wikipedias, along with workers from Amazon Mechanical Turk, for helping with data labeling and for their precious suggestions.


